XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。
XGBoost的基本思想和GBDT相同,但是做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。
XGBoost具有高效、灵活和轻便的特点,在数据挖掘、推荐系统等领域得到广泛的应用。
XGBoost 基础
GBDT 梯度提升决策树
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于 Boosting 集成思想的假发模型,训练时采用向前分布算法进行贪婪的学习,每次迭代都学习前一棵 CART 树来拟合前 t-1棵树的预测结果与训练样本真实值的残差。
假如我们有 个样本,每个样本的特征空间都是 N 维(每个样本都有 N 个特征值,每个特征代表一个维度),并且每个样本都有自己所对应的的标签 ,用数学语言来描述就是:
存在训练样本集
其中每一个样本 都是一个 维的向量,即:
用更直观的表示方式为:
我们进行训练的目的,是为了找到一个预测函数 (这里的 其实不能算是函数,因为它是决策树的叶子节点的预测值。为了方便,这里展示叫做函数) ,使得 的值与样本的标签值 之间的误差最小,即损失函数 能够取得最小值。
GBDT 算法过程如下:
输入:训练集 ,损失函数 ;
输出:回归树 ;
一、初始化弱学习器
这里很容易理解,我们在初始化弱学习器的时候,只需要最简单的,让初始的预测函数 ,即不管输入的样本是什么,初始化的预测函数 都只输入常数 。因此只要找到一个常数 使得损失函数最小,将其作为初始化的学习器即可。
假设损失函数为平方损失,即:,因为平方损失函数是一个凸函数,因此直接对 求导:
令导数为 0,得:
即 取训练样本标签值的平均数即可。
此时得到初始学习器:
二、迭代训练 棵树
(a) : 在第 次训练时,对每个样本 ,计算负梯度,即残差:
(b) : 将 (a) 得到的残差 作为样本新的真实值,形成新的样本集 。将新的样本集 作为新的训练集,得到新的回归树,其对应的叶子节点区域 。其中 为新回归树的叶子节点的个数。
(c) : 对第 棵树的 个叶子节点,通过在每个叶子节点内的样本来计算最佳拟合值:
(d) : 更新学习器:
其中, 为指示函数,即:
为了能够更清晰的明白以上迭代的过程,接下来,我们将以迭代过程展开计算两次次迭代,来帮助理解这个过程。
首先要知道的是,以上迭代过程依赖于决策树,在此,对决策树的具体构造方式不进行展开解释,后面会有决策树的构造方式。
在此,我们假定针对每一次迭代,都有一定的策略生成一棵决策树。
针对第 0 次迭代,也就是初始化时,我们生成的决策树为:

如上图所示,蓝色的节点为决策树的叶子节点,所有的样本 都落在叶子节点中。而每一个叶子节点,都有一个值 作为决策树的预测值。在第一步初始化学习器的时候,我们知道,每个节点的 。
在第一次迭代时,根据 (a)来计算每个样本的残差,在这里,我们仍然使用平方损失作为损失函数 (当然,也可以使用其他的损失函数,这里只是为了演示计算过程方便而选择了平方损失),那么可以计算出每个样本的残差为:
当然,此处的 为初始化即第 0 次迭代时得到的值,即: 。
由此,我们得到了第 1 次迭代的每个样本的残差 。并根据步骤(b)将每个样本的残差作为真实值,形成新的样本集:
然后使用 通过一定的策略生成新的决策树:

根据 (c)遍历每一个节点,通过每一个节点内的样本,计算出该节点的最佳拟合值,然后根据步骤 (d)来更新这棵树每个节点的预测值。
值的注意的是,除了初始化的时候,对每个样本的预测值 相同外,在第 1 次迭代后,因为每个样本所在的叶子节点不同,叶子节点内的残差也是不尽相同的,因此第 1 次迭代后每个样本的预测值也就不同了,因此在后续的迭代过程,就相当于对 的迭代。
三、得到最终的学习器 GBDT
即经过 次迭代后,最终的预测值,就是 的预测值加上 棵树的预测值的和。这是因为只有在初始化的那一次,决策树的预测值代表着对样本的预测值,后续迭代生成的决策树的预测值,都是对上一次决策树的残差的预测。
在这里展开一下决策树的大致工作原理。
我们可以将决策树理解为一个筛选器,除了叶子节点外的节点,其余的每个节点的作用都是进行条件的筛选。可以理解为一个样本落入一个决策树时,先经过根节点的筛选,然后根据筛选结果,落入根节点对应的子节点内。然后再由该节点进行条件筛选,样本再落入其对应的子节点内。
以此类推,直到样本落入叶子节点内,要注意的是,一个样本经过筛选后,只能落入其中的某一个叶子节点,不会出现一个样本落入两个不同叶子节点的情况。而叶子节点又有一个值,落入该叶子节点,就代表该样本属于该叶子节点,那么该叶子节点的值就代表着对样本的预测结果。
如下所示:
如上左图对“小明”这个样本的胖瘦判断。当然,上左图是一个分类树的示意图。对于回归树,其大致流程与分类树一致,只不过回归树的叶子节点的的分类变成了预测值,如上右图,即预测 。
这样,我们其实更能明白所谓函数 是一个决策树而非函数这个概念了。
那么对于 GBDT 树而言,它做了什么呢?
首先我们看第一课树,它的训练集是 ,那么训练完成后,每个样本都呆在某个叶子节点中。而样本所处的叶子节点的值,就是对样本 的预测值 ,用数学的描述就是 。
当然,对于回归树而言这个预测值是与真实的 存在一定的误差的,即存在残差:
那么对于第一课树而言,残差为:
那么可能会有个疑问,那就是 应该是一个常数啊,为什么对常数求偏导应该是 0 啊。
这里要弄明白的是, 是一个常数,代表着 的值是常数,但是对于损失函数而言 只是一个变量。
比如说最简单的函数 , 是一个常数,这并不意味着我们就没办法对 进行求导了,因为对于函数 而言,它才不管 等于几,在它看来, 就是一个变量。
在训练第二棵树的时候,输入的训练集不再是 ,而是 ,因此,第二棵树的叶子节点的值 不再是对 的预测,而是对第一棵树的产生的残差 的预测。
因此,现在需要这两棵树共同“协作”才能得到真正的预测值,即:(注意,这里 的上标不是平方的意思,而是代表是第 2 棵树的预测值)。
同样的,第二棵树的预测值 与第一课树产生的残差之间仍有误差,那么继续将第二棵树的残差作为新的训练集训练第三棵树,然后以此类推,训练出更多的树。
那么为什么要训练出很多棵树来对 进行预测呢?换句话所,这样做对预测有什么帮助呢?
我们首先来看一下每一棵树的叶子节点的组成。
对于第一课树而言,它的每个叶子节点内有着大量的样本,假设我们有一个函数 ,它是样本 和其所在叶子节点的映射,也就是说,当第一棵树构建好后,我们可以通过 来找到样本 在哪个叶子节点中。如样本 在第 7 个叶子节点中,那么 。
那么对于第 个叶子节点,它其中包含的样本就可以用集合表示为 。
对于第 个叶子节点,它的值是由该叶子节点内的所有样本 对应的标签值 所共同决定的。
换句话说,第 个叶子节点的值,是经过该叶子节点内的样本的 经过一系列运算得出的。
对于第二棵树,其训练数据已经变成了样本和第一棵树的预测值的残差,由于训练数据不同,导致形成的树的结构也与第一课树不同。
比如第一棵树有 20 个叶子节点,第二棵树可能只有 13 个叶子节点。
比如第一棵树的第一个节点内的样本为 ,第二棵树的第一个节点内的样本可能是 。
对同一个样本而言,它落入两棵树的叶子节点也可能是不同的。
比如对于样本 ,它在第一棵树中可能落入第一棵树的第 9 个叶子节点,与它为伴的,同样落入第 9 个叶子节点的样本可能还有 ;
那么 它在第二棵树中可能落入第 3 个叶子节点,在第二棵树的第 3 个叶子节点中与它为伴的可能就变成了 。
那么 与 的值就由各自的叶子节点内的样本所决定。
如果我们将一棵决策树进行一系列筛选的过程看作某种衡量,那么落入同一个叶子节点的样本,可以视作通过这种衡量,具备一定的相似性。
而在第二棵树,其训练数据已经变成了样本和第一棵树的预测值的残差,再经过第二棵树的衡量,落在同一个叶子节点内的样本也具有相似性。
经过很多棵的树,我们可以认为是通过很多种不同维度的衡量,得出了很多种不同衡量方式下的样本的不同的相似性(一种衡量对应一种相似性)。
那么经过多棵树在多个维度的衡量,衡量的维度越多,说明我们对样本的分析越全面,进而能够得出更好的预测效果。

XGBoost 原理
相比于 GBDT ,XGBoost 在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的 score 的二范数。
同时,XGBoost 支持用户自定义目标函数和损失函数,只要目标函数和损失函数二阶可导就行。
目标函数推导
已知训练集 ,损失函数 ,正则化项 ;
则整体目标函数可记为:
其中:
为目标函数;
为第 个样本 对应的的真实标签值, 为第 个样本 的预测值, ;
为第 棵树, 标识第 棵树的复杂度, 代表 棵树总的复杂度。
用 GBDT 梯度提升树表达方式来表达 XGBoost:
由于在 GBDT 中:
则目标函数转为:
这里值的注意的是, 衡量的是整个模型,也就是所有树的总体目标函数。而 衡量的是第 次迭代,也就是第 棵树。
目标函数优化
接下来,分三个步骤优化目标函数。
一:二阶泰勒展开,去除常数项,优化损失函数:
我们知道,具有连续二阶导数的函数 在 处进行二阶泰勒展开为:
假设 ,对其在 处展开有:
因此,对 在 处的展开为( 是已知的):
记一阶导为 ,二阶导为 ,并将上式代入目标函数可得:
二:正则化展开,去除常数项
因为算法的过程是向前计算,即在计算第 棵树时,已经假定前 棵树的结构是已经确定的了,因此 是已知的。同样的, 也是已知的,视作常数项,那么它对于我们的目标函数的优化没有影响。因此目标函数化简为:
将正则项,即树的复杂度拆分得:
因为前 棵树的结构是已经确定的了,因此前 棵树的复杂度也是确定的,可以看作常数。
则目标函数可以进一步化简为:
三:合并一次项系数、二次项系数
首先我们先看一下按某个策略构造出的决策树:

决策树包含两个部分:
1、叶子节点权重向量 ,每个叶子节点都有一个权重值 ,这些权重值共同组成了决策树的叶子节点权重向量 (同时,每个叶子节点的权重 的值也就是该棵树对落在该叶子节点内的样本的预测值);
2、叶子节点与样本的映射关系 ,即给定某个样本 ,能够通过 得到该样本位于哪个叶子节点中。
那么这棵树可以被描述为:
其中, 表示这棵树有 个叶子节点。
上式所描述的决策树很简单,就是通过映射关系 ,得到样本所在的节点的权重。
接下来定义树的复杂度 ,它由两部分组成:
1、叶子节点的数量;
2、叶子节点权重向量的 范数。
这里简单介绍一下 范数和 范数:
我们来看一下正则项(惩罚项)是如何影响目标函数的优化的。
我们知道,除了第一棵树,后续的所有的树的叶子节点的值,也就是权重 都代表上一棵树预测结果的残差。
因此,我们希望每棵树的残差也就是 越小越好,理想情况下, 应该趋向于 0。而当某个叶子节点的 越大, 也就越大 ,代表着残差变大了。
因此,将 作为惩罚项。
而另一项 , 代表叶子节点的个数,叶子节点越多,树的结构越复杂。
即通过叶子节点的个数 和决策树的叶子节点权重向量二范数 来共同组成决策树的复杂度定义。
其中, 为系数,可以理解为敏感度。
代入目标函数得:
可以看到,上式中前半部分 是从遍历样本的角度来描述的,后半部分 是从决策树的叶子节点的角度来描述的。为了统一,我们换一种方式来描述上式。
我们知道,决策树构建完成后,所有的样本都落入叶子节点中,且每个叶子节点中的样本不重复,每个样本也只能落入某一个叶子节点中。因此,我们将落入第 个叶子节点的所有样本 划入到一个集合中,数学描述如下:
我们把 中遍历所有样本改为遍历所有叶子节点的集合 ,得到:
我们令:
:叶子节点 中所包含样本的一阶偏导数累加之和,是一个常数;
:叶子节点 中所包含样本的二阶偏导数累加之和,是一个常数;
将其带入目标函数得:
以上就是 XGBoost 的最终目标函数。可以看到,上式中,变量只剩下第 棵树的权重向量 。
目标函数求解
在前面,我们将样本遍历的方式变换成了叶子节点遍历,这样做还有一个好处,那就是方便我们进行求解。
我们观察一下最终的目标函数,其实我们的目标函数就是一个关于向量 的函数。对于每一个叶子节点 而言,其权重 都是标量,且每个叶子节点相互独立,那么我们将目标函数写为关于 的函数形式:
又已知每个叶子节点都是相互独立的,那么:
即求总体目标函数的最小值可以通过贪心的方式,求每一个叶子节点的最小值来获得。
而对于其中的某个叶子节点 :
其实就是一个关于标量 的一元二次函数:
而 ,则 在 处取的最小值 。
回顾一下 :
$h_i$ 为叶子节点 $j$ 内的样本 $x_i$ 的损失函数 $L(y_i, \hat{y_i}) = L(y_i, \hat{y_i}^{(t - 1)} + f_t(x_i))$ 在 $\hat{y_i}^{(t - 1)}$ 处的展开式中的二阶导,即:
而损失函数为凸函数,因此其二阶导大于 0;
而 $H_j$ 为叶子节点 $j$ 内的所有二阶导之和,因此:$H_j > 0$;
$\lambda$ 在定义时就有 $\lambda \geq 0$,因此 $H_j + \lambda > 0$。
因此,关于目标函数则有最优解:
目标函数最优值:
也就是说,对于每个决策树,其第 个叶子节点的权重的值取 时,目标函数有最优解。
决策树构建策略
经过前面的推导和求解,我们已经知道了某棵决策树的叶子节点的最优解的权重,然后可以计算出该棵树的目标函数值。
对于不同的决策树,其形状不同,样本在叶子节点中的分布也不同,叶子节点的最优权重也不同,导致用来衡量整棵树的目标函数最优值也不同。可以构造不同的树,计算各自的目标函数的最优值,选取最优值最小的树。
但是这里有一个问题,那就是我们在实际应用中,无法做到遍历所有的树形结构,计算所有树形结构的目标函数值,从而选出最小的那个。因此我们接下来要做的就是:如何高效地构造出一个决策树。
接下来,将介绍使用贪心算法和加权分位法来构造决策树。
贪心算法
简单点来讲,就是保证每一步都是最优解,从而达到全局最优解的方法。也就是说,在决策树生成的过程中,保证每一次节点的分裂而产生的新的树,都是目标函数最小的。
假设我们的样本有 四个特征,我们首先要构造决策树的第一层。分为一下三个步骤:
Step 1、分别将每个特征依次作为第一层节点,分裂出下层节点(如何选择分裂点的值在后面会讲到);
Step 2、将 Step 1 中分裂出的节点当作叶子节点,计算权重 及目标函数值 ;
Step 3、选择目标函数值 最小的。

如上图所示,依次选取 四个特征作为决策树的第一层,得到对应的叶子节点。每个叶子节点计算出相应的权重 ,然后根据叶子节点的权重计算出目标函数的值。可以看到,将特征 作为节点进行分裂得到的 是最小的,因此,就将特征 作为决策树的第一层。
那么我们该如何判断某个节点是否需要进行分裂呢?这里我们与传统的决策树一样,使用增益来作为判断依据。
只有当这个节点分裂后,形成的新的树的目标函数值比之前的小,才进行分裂。
假如我们有一个节点 ,该节点包含的全部样本集合为 ,那么我们可以计算出该节点的目标函数最优值(将该节点当作一个只有一个叶子节点的树,通过最终的目标函数进行计算即可):
现在假设要将 分裂出左节点 和右节点 ,左节点 所包含的样本集合为 ,右节点所包含的样本集合为 。

分别计算左节点和右节点的目标函数最优值:
那么分裂增益就为:
也就是说只有当 时,才进行分裂。
在这里就可以看出惩罚项 的作用了,当因为分裂不仅代表着增益的增加,也代表着树的复杂度增加。
我们将分裂带来的树的增益看作收益 ,将分裂导致树的复杂度的增加看作损失 , 就是我们对损失的容忍度,也就是给损失加了一个系数,那么我们预期的整体收益为:
只有当预期的整体收益为正时,才进行分裂。
当然,是否该对接节点进行分裂还有其他的限定条件,如树的层数限制、整体的树的叶子节点的个数限制、该节点中样本数量的限制等等。
接下来,只要重复上述步骤,就可以构建出第二层、第三层···决策树了。直到样本的所有特征都被使用,或已经达到了限定的层数。
加权分位法
前面我们描述了使用贪心算法来构建决策树的过程,但是并没有对一个节点内的特征值的分裂点的选择进行说明。加权分位法就是用来计算最佳分裂点的。
什么是最佳分裂点呢?在前面,我们选择特征 来进行分裂,假设特征 是一个离散的连续变量,有 5 个不同的值,范围是 ,那么在选取特征 进行分裂时,需要尝试 ,共 5 种情况下的划分,然后分别计算目标函数值,选取目标函数值 最小的一个划分所形成的分裂树。

当然,在特征的值的范围比较小的情况下,也就是划分情况比较少的情况,我们可以使用穷举的方式,计算每一种划分的目标函数值,选取最小的。但是当划分情况比较多的时候,这种做法无疑是低效的。
那么,能否有什么好的方法,可以不用尝试遍历每一种划分,只选取几个划分进行尝试?为了解决这个问题, XGBoost 使用了一个全新的方法 : 加权分位法。
数学原理
我们先看一下化简得到的目标函数:
我们将目标函数变换一下形式:
其中 为常数,因此上式化简为:
PS : 在原论文中,将上式化简为:
如下图所示:
暂时没有想明白为什么 差了个负号,但是这一步只是示意,并不会依托其进行具体的运算,因此不会对后续的结果产生影响。

可以看出,上式的目标函数是一个以 为真实值,以 为权重的平方损失函数。因此,我们可以得出结论:一个样本对目标函数的贡献,在于其得到的 。
这样,我们就可以根据 对特征值的“重要性”进行排序。 XGBoost 提出了一个新的函数,这个函数用于表示一个特征值“重要性”的排名:
其中:
1、 为第 个特征的每个样本的特征值 与其对应的 组成的集合。 标识第一个样本对于第 个特征的特征值,和其对应的 ;即:
2、 的分母为第 个特征的所有样本的 的总和;分子为所有特征值 小于 的样本的 的总和;
这里不太好理解,我们将上面的式子拆开来理解。
首先我们将第 个特征的值想象成一个数轴,每个样本在第 个特征上的特征值为数轴上的一个个散点(当然,有可能不同的样本在 上的特征值相同,也就是每一个散点可能代表着不止一个样本):
同时,每个样本 都对应着一个 ,因此, 就是上面所有散点对应样本的 的集合(同样的,一个散点可能代表多个样本,一个散点也可能代表着多个 )。
分母 就代表着所有的全部散点(绿色 + 黑色)对应的 之和。
而对于分子 ,就是样本在 上的特征值小于 的所有散点(绿色)对应的 之和。
因此, 其实求的就是不同的取不同的 之时,所有绿色散点的 之和与所有散点的 之和的比值。

之后,按照上面的公式求出一个特征的所有特征值对应的 ,并对其进行排序。
在排序之后,设置一个值 。这个值用于对要划分的点进行规范,满足条件如下:
对于特征 的特征值的划分点 , 要求两个相连的划分点的 值的差的绝对值要小于 。也就是说,每两个相连的划分点之间的“间隔”不能太大,而这个“间隔”就是两个划分点对应的 之间的差,即:
即如上图所示,两个相邻的切分点 之间的散点(绿色)所对应的占比不能太小。
同时,为了增大算法的效率,也可以选择每个切分点包含的特征值数量尽可能多。也就是说,在满足上面的条件的情况下,相连的两个切分点之间要包含尽可能多的特征值,也就是让 尽量大,也就是说让 和 的间隔尽可能的大。
换句话说,就是对 排完序后,大约要选出 个切分点。

作用
使用加权分位法的分裂点之后,在贪心酸的的分裂过程中,我们只需要对这几个分裂点进行尝试,而不需要与原先一样,对所有特征值进行尝试,这将大大减少算法的开销。
策略
基于加权分位法,我们有两种策略进行分裂点的计算:1、全局策略;2、局部策略。
全局策略
顾名思义,全局策略,我们在一棵树的生成之前,就已经计算好每个特征的分裂点。并且在整个树的生成过程当中,用的都是一开始计算的分裂点。这也就代表了,使用全局策略的开销更低,但如果分裂点不够多的话,准确率是不够高的
局部策略
局部策略,对每一个结点所包含的样本,重新计算其所有特征的分裂点。我们知道,在一棵树的分裂的时候,样本会逐渐被划分到不同的结点中,也就是说,每个结点所包含的样本,以及这些样本有的特征值是不一样的。因此,我们可以对每个结点重新计算分裂点,以保证准确性,相当于是因地制宜的方法。这也就代表了,使用局部策略的开销更大,但分裂点数目不用太多,也能够达到一定的准确率。
在原论文中,使用不同的策略的预测效果如下图:
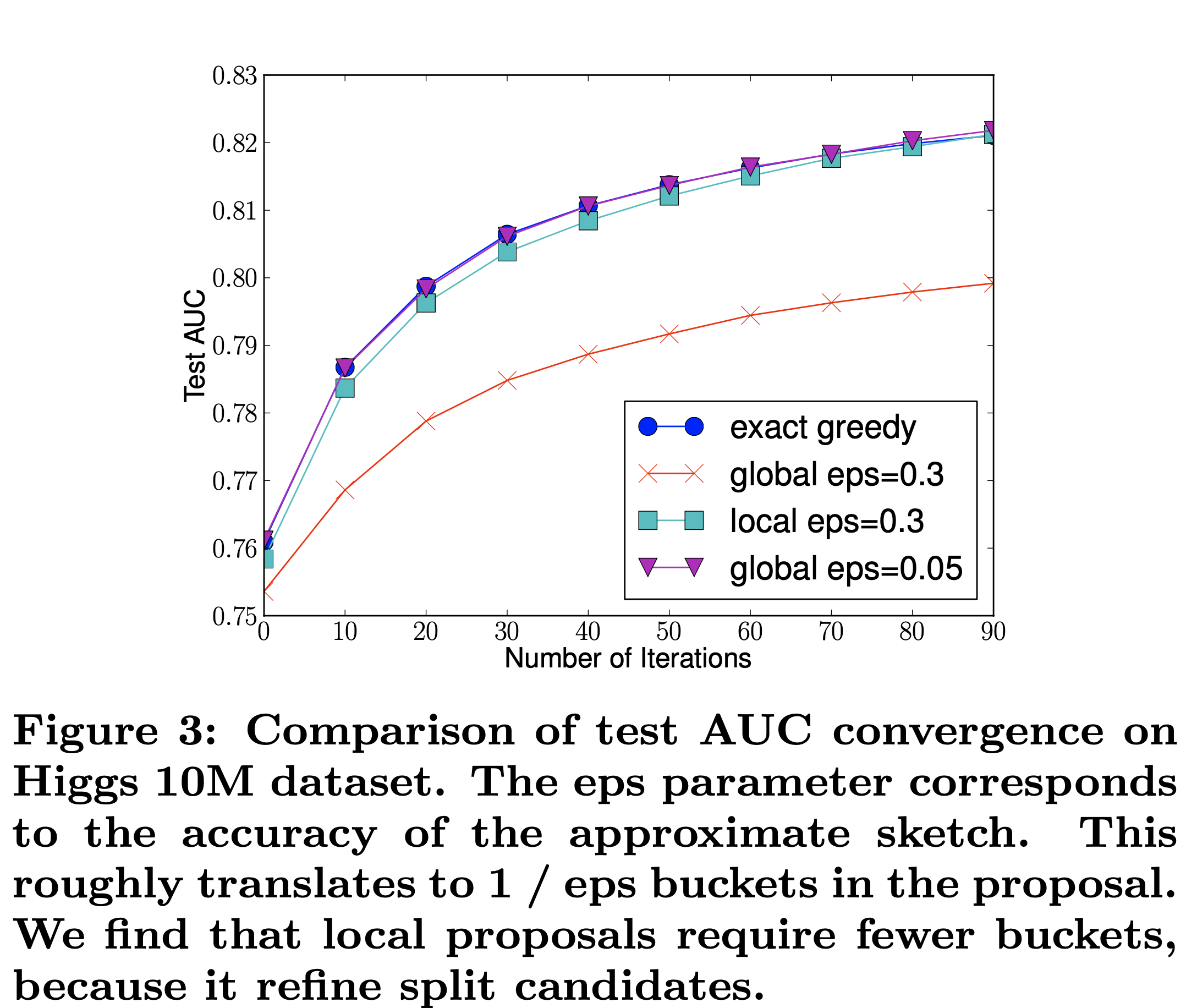
根据上图,我们可以得出结论:
1、在分裂点数目相同,即 相同的时候,全局策略的效果逊于局部策略;
2、分裂点数目越多,两个策略的效果都越好;
3、全局策略可以通过增加分裂点数目,达到逼近局部策略的效果。

